
システム屋であれば必須のスキルに「データの正規化」というものがあります。
昔会社の大先輩に「システムを設計することはデータを設計すること」というありがたい教えを受けた時は「何のこっちゃ?」と思いましたが、経験を重ねる上で「本当にそうだなぁ」と思うようになりました。
データ正規化(第三正規形)については様々なサイトや動画で詳しく説明してくれていますので、考え方/やり方についてはそちらに譲らせていただくとして、今回は正規化の説明では語られない実務ベースに必要となる+αの考え方について解説したいと思います。
例えば以下のような受注伝票を正規化しテーブルに格納することを考えてみましょう。
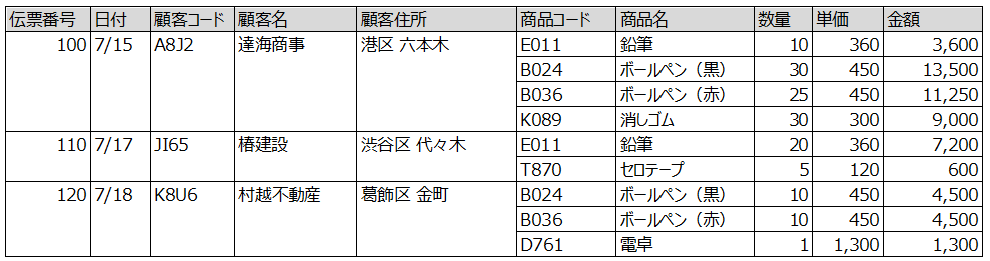
「くり返し」を排除し「部分従属」の排除し「関数従属」を排除して、多くの解説で以下のような形で正規化するよう説明がなされています。
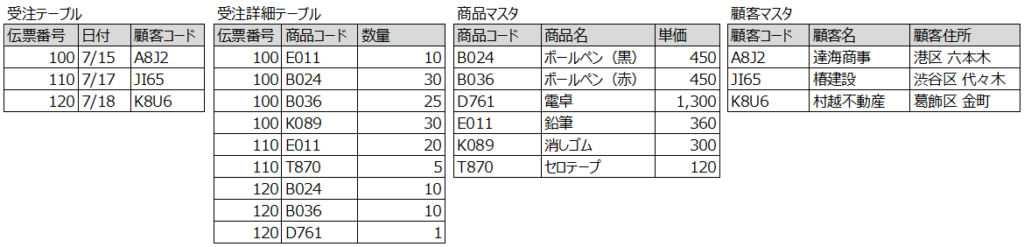
でもちょっと待ってください。これで大丈夫でしょうか? 以下のようなことが発生したらどうするのでしょうか?
・商品の単価が変更されたら・・・
=>過去の伝票を確認しても、その時の合計金額が分からなくなる
・顧客の住所が変更されたら・・・
=>商品をどこに届けたのか分からなくなる
それでも問題がないというケースもあるかもしれませんが、上記のことを考えるとこのテーブル設計がとても実際の運用に耐えるとは思えません。
上記のような要素を考慮すると、受注テーブルと受注詳細テーブルは以下のような設計になります。
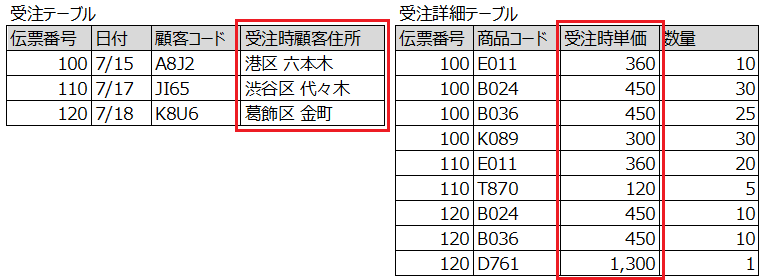
お気づきだと思いますが、一見同じ項目だと思われた「商品単価」は、商品マスタ上の物と受注詳細テーブル上の物では意味合いが違うということです。(顧客住所も同様)
さらに、商品の単価が変更になった後に変更前に受注した伝票を入力しなければいけないケースも考えると商品マスタは以下の2テーブルに分割しておく必要があります。
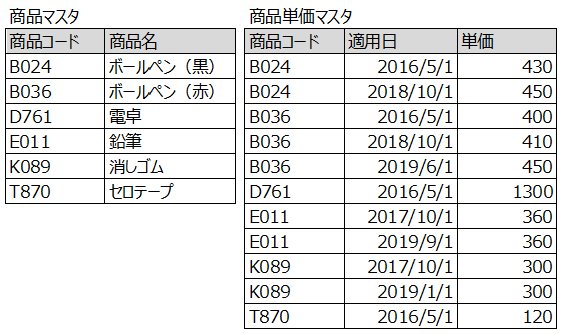
実践的なテーブル設計をするために・・・
このような実践的なテーブル設計を行うためにご留意いただきたい点は以下の通りです。
・各データ項目が今後変更される可能性があるか?
・データ項目が変更された場合に不都合が発生することはないか?
このように考えることで、正規化の有効性を活用しつつ実践的なテーブル設計ができるようになると思います。
逆に「変更されない項目」については?
逆に変更されることのないデータ項目であれば、多少冗長に持ったとしても問題は発生しません。処理速度や使い勝手などを考慮して多少正規化を崩すことも実践的なテーブル設計のアプローチといえます。
ちょっと昔話
データの正規化が提唱され始めた時代は、まだまだ記憶媒体の単価が高くコストの削減も冗長化排除の目的となっていましたが、記憶媒体コストが劇的に下がってしまった現在では費用のことをあまり気にせず(あえて冗長化を残す)適切なテーブル設計ができるようになった背景もご認識いただければと思います。


コメント